


很多人在买完高端双程优化线路的 VPS(推荐VPS实时监控网:https://vpsing.de),搭建完代理节点后,都会纳闷一个问题:
“为什么我的 ping 值延迟明明很低,但看 4K 视频还是会频繁卡顿转圈?”
今天我们用最通俗的语言,聊聊 Linux 内核网络调优到底在调什么,以及为什么它是压榨出跨境链路带宽极限的最后一公里。
🛑 默认内核的两大“带宽黑洞”
很多人不知道,Linux 默认的网络内核参数,是二十多年前为局域网或低带宽环境设计的。在动辄 1Gbps 的现代跨国公网面前,存在两个致命瓶颈:
1. 缓冲区太小:大马拉小车
当你用默认参数跑代理时,网络通信就像是用吸管喝水。哪怕你源站 VPS 的带宽是 1Gbps(消防水管),但 Linux 默认的 TCP 发送/接收缓冲区(Buffer) 极其狭窄。
数据只能一小勺一小勺地喂给客户端,导致长距离高带宽(LFN)网络的传输效率直接被死死锁上限。
2. 悲观的拥塞算法:见丢包就“自残”
Linux 默认的旧版拥塞控制算法(如 Cubic)行为非常悲观:
只要跨境链路稍微出现一点点数据丢包,它就会惊慌失措,误以为网络彻底瘫痪。
随后,它会直接主动把发送速度砍掉一半!
在晚高峰的跨境公网中,由于各种网络干扰,5% 以内的随机丢包再正常不过。Cubic 这种“一见丢包就自残”的机制,就是你刷视频不断断流的罪魁祸首。
🛠️ TCP 调优到底在干什么?
针对上述痛点,网络调优本质上是在内核底层完成两项史诗级重构:
1️⃣ 魔改缓冲区强行调大 rmem 和 wmem 最大内存限制将 TCP 窗口(Window Size)彻底撑开,把饮水吸管直接换成消防水管。
2️⃣ 激活 BBR 引擎开启 Google 研发的 BBR 拥塞控制算法不再盲目根据丢包减速,而是实时测量物理链路的真实容量与延迟。只要管道没满,哪怕有丢包,依然开足马力顶着极限速度发送数据!
# 开启 BBR 拥塞控制
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
# 极大化 TCP 读写缓冲区,专治大带宽长延迟(LFN)网络
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
# 优化滑动窗口与快重传
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_sack = 1💾 VPS TCP 调优面板
只需要在服务器窗口执行:
bash <(curl -sL tcp.vpsing.de) 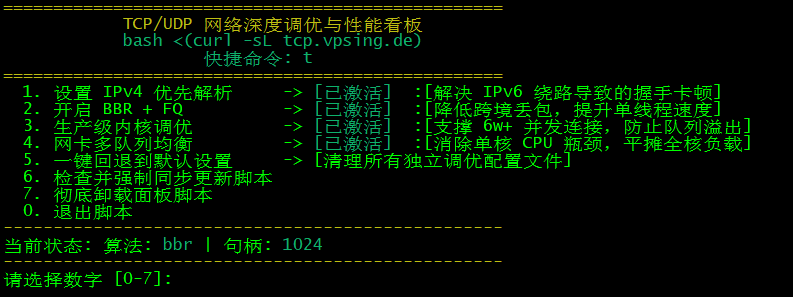
依次按照1-4的步骤,即可深度调优。以后就可以通过快捷快 t,直接调出面板。
评论区